拆拆 iOS 数据持久化
持久存储是一种非易失性存储,在重启设备时也不会丢失数据。Cocoa框架提供了几种数据持久化机制:
1)属性列表;
2)对象归档;
3)iOS的嵌入式关系数据库SQLite3;
4)Core Data。
在iOS开发中,持久化数据的方法也并不限于属性列表、对象归档、SQLite3和Core Data。它们只是四种最常用且简单的方法。其实也可以使用传统C语言I/O调用(比如,fopen())读写数据,也可以使用Cocoa的底层文件管理工具。只不过这两种方法都需要写很多代码,并且没有必要这么做。
一、应用的沙盒
Cocoa提供的四种数据持久化机制都涉及一个共同因素,即应用的/Documents文件夹。每个应用都有自己的/Documents文件夹,且能读写各自的/Documents目录中的内容。
为了便于理解,我们先来看一下iPhone模拟器使用的文件夹布局,从而了解iOS中应用是如何组织的。打开Finder窗口,找到主目录,找到Library(资源库)目录,找到Developer/CoreSimulator/Devices/,在该目录中可以看到一些子目录,分别对应Xcode中的模拟器。子目录的名称是Xcode自动生成的GUID(Globally Unique Identifier,全局唯一标识符),因此无法确定每个目录对应哪一个模拟器。解决这个问题的方法是找到模拟器目录中名为device.plist的文件,并打开它,就可以看见一个对应模拟器设备名称的键。
虽然这是模拟器的目录,但实际设备上的文件结构与此相似。如果想看到设备上应用程序的沙盒,就将它连接到Mac上并打开Xcode的Devices窗口,在窗口边侧栏可以看到该设备,选中它然后在Installed Apps表中选择一个应用程序。在表的下方有一个看起来像齿轮的图表。点击它并在弹出菜单中选择Show Container选项就可以看到应用程序沙盒的内容。
每个应用程序沙盒都包含以下三个目录:
1)Documents:应用程序可以将数据存储在Documents目录中。如果这个应用程序启用了iTunes文件分享功能,用户就可以在iTunes中看到目录的内容(以及应用程序创建的所有子目录),还可以对其更新文件。
如果要为应用程序启用文件分享功能,需要打开它的Info.plist文件并添加键为Application supports iTunes file sharing值为YES的条目。
2)Library:应用程序也可以在这里存储数据。它用来存放不想共享给用户的文件。需要时可以创建自己的子目录。系统创建了名为Cache和Preferences的子目录。后者包含了存储应用程序偏好设置的plist文件,通过NSUserDefaults来操作。
3)tmp:tmp目录供应用存储临时文件。当iOS设备执行同步时,iTunes不会备份tmp中的文件。在不需要这些文件时,应用要负责删除tmp中的文件,以免占用文件系统空间。
获取Documents目录
1 | NSArray *paths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES); |
常量NSDocumentDirectory表明我们正在查找Documents目录的路径。第二个常量NSUserDomainMask表明我们希望将搜索限制在应用的沙盒内,在OS X中表明我们希望该函数查看用户的主目录。
1 | NSString *filename = [documentsDirectory stringByAppendingPathComponent:@”theFile.txt”]; |
完成此调用之后,filename就包含了指向应用Documents目录中theFile.txt文件的完整路径。
获取Library目录
1 | NSArray *paths = NSSearchPathForDirectoriesInDomains(NSLibraryDirectory, NSUserDomainMask, YES); |
常量NSLibraryDirectory表明我们正在查找Library目录的路径。第二个常量NSUserDomainMask表明我们希望将搜索限制在应用的沙盒内,在OS X中表明我们希望该函数查看用户的主目录。
获取tmp目录
1 | NSString *tempPath = NSTemporaryDirectory(); |
二、文件保存方案
Cocoa提供的四种实现数据持久化的方法,都使用iOS的文件系统。使用SQLite3将创建一个SQLite3数据库文件,并让SQLite3去存储和检索数据。Core Data则以其最简单的形式帮助开发者完成所有的文件系统的管理工作。使用属性列表则需要考虑将数据存储在一个文件中,还是存储在多个文件中。
单文件持久化
把数据保存在一个文件中是最简单的方法,而且对于许多应用,这也是完全可以接受的方法。首先,创建一个根对象,通常是数组或字典(使用归档容器的情况下根对象可以给予这个自定义类)。接下来,使用所有需要保存的程序数据填充根对象。真正保存时,代码会将该根对象的全部内容重新写入单个文件。应用在启动时会将该文件的全部内容读入内存,并在退出时注销。
使用单文件的缺点:必须将全部数据加载到内存中,并且不管有多小的更改也必须将所有数据全部重新写入文件系统。
多文件持久化
使用多文件持久化是另一种实现持久化的方法。例如,电子邮件应用可能会将每封邮件都单独存储在一个文件中。
这种方法的优点,例如应用可以只加载用户请求的数据(另一种形式的延迟加载),当用户进行更改时只保存更改的文件。此方法允许开发者在收到内存不足通知时释放内存。用户当前未查看的任何数据都可以从内存中删除,下次需要时再从文件系统重新加载即可。
使用多文件持久化的缺点:它大大增加了应用的复杂性。
三、属性列表
属性列表使用起来非常方便,可以使用Xcode或Property List Editor应用手动编辑它们。而且只要字典或数组包含特定可序列化对象,就可以将NSDictionary和NSArray实例写入属性列表或者从属性列表创建它们。
属性列表序列化
序列化对象,是指可以被转换为字节流以便于存储到文件中或通过网络进行传输的对象。虽然任何对象都可以被序列化,但是只有某些对象才能放置到某个集合类中(如NSDictionary或NSArray中),然后才使用该集合类的writeToFile:atomically:或writeToURL:atomically:方法将它们存储到属性列表中。可以按照该方法序列化下面的类:
1)NSArray、NSMutableArray
2)NSDictionary、NSMutableDictionary
3)NSData、NSMutableData
4)NSString、NSMutableString
5)NSNumber
6)NSDate
如果只使用这些对象构建数据模型,就可以使用属性列表来方便地保护和加载数据。如果打算使用属性列表持久保存应用数据,则可以使用数组或字典。假设放到字典或数组中的所有对象都是前面列出的可序列化对象,则可以通过对字典或数组的实例调用writeToFile:atomically:方法来写入属性列表。
1 | [myArray writeToFile:@”/some/file/location/output.plist” atomically:YES]; |
说明:这里的atomically参数让该方法将数据写入辅助文件,而不是写入指定位置。成功写入该文件之后,辅助文件将被复制到第一个参数指定的位置。这是更安全的写入文件的方法,因为如果应用在保存期间崩溃,则现有文件(如果有)不会被破坏。尽管增加一点开销,但是多数情况下还是值得的。
属性列表方法的一个问题就是,无法将自定义对象序列化到属性列表中,另外也不能使用没有在可序列化对象类型列表中指定的Cocoa Touch的其他类。这意味着无法使用NSURL、UIImage和UIColor等类。
且不说序列化问题,将这些模型对象保存到属性列表中还意味着无法轻松创建派生的或需要计算的属性(例如,等于两个属性之后的属性),并且必须将实际上应该包含在模型中的某些代码移动到控制器类。这些限制也适用于简单数据模型和简单应用。但在多数情况下,如果创建了专用的模型类,则应用更容易维护。
在复杂的应用中,简单属性列表仍然非常有用。它们是将静态数据包含在应用中的最佳方法。例如,当应用包含一个选取器时,创建一个属性列表文件并将其放在项目的Resources文件夹中,就是将项目列表包含到选取器中的最佳方法,这样能把项目列表编译到应用中。
NSData
NSData主要是提供一块原始数据的封装,方便数据的封装与流动,比较常见的是NSString/NSImage数据的封装与传递。在应用中,最常用于访问存储在文件中或者网络资源中的数据。
这个类提供的封装/解封方法:
1 | +(id)dataWithBytes:(const void *)bytes length:(NSUInteger)length; |
从这几个方法可以看出,NSData根本不管传递的内容到底是什么,仅仅是传递一块内存——仅需内存的起始地址和长度。
解析plist
1 | idresult = [NSPropertyListSerialization propertyListWithData:data options:0format:NULL error:NULL]; |
读写plist
1)写入文件
1 | NSArray*phrase; |
现在看一下文件/tmp/verbiage.txt,
1 | <?xmlversion="1.0" encoding="UTF-8"?> |
这些属性列表文件可以为任意复杂的形式,可以是包含字符串、数字和日期数组的字典数组。Xcode还包含一个属性列表编辑器,所以可以查看plist文件并进行编辑。
说明:有些属性列表文件(特别是首选项文件)是以压缩的二进制格式存储的。通过使用plutil命令:plutil -convert xml1 filename.plist,可以将这些文件转换为人们可读的形式。
2)读取
之前已经将verbiage.txt文件存放在磁盘上,可以使用+arrayWithContentsOfFile:方法读取该文件。代码如下:
1 | NSArray*pharse = [NSArray arrayWithContentsOfFile:@"/tmp/ verbiage.txt "]; |
说明:注意到writeToFile:方法中的单词atomically了吗?这种调用有什么负面作用吗?没有。atomically:参数的值为BOOL类型,用于通知Cocoa是否应该首先将文件内容保存在临时文件中,当文件成功保存后,再将该临时文件和原始文件交换。这是一种安全机制:如果在保存过程中出现意外,不会破坏原始文件。但这种安全机制需要付出一定的代价:在保存过程中,由于原始文件仍然保存在磁盘中,所以需要使用双倍的磁盘空间。除非保存的文件非常大,将会占用用户硬盘空间,否则应该自动保存文件。
如果能将数据精简为属性列表类型,则可以使用这些非常便捷的调用来将内容保存到磁盘中,供以后读取。如果你正在从事一项新创意或设计一个新项目,可以使用这些便捷方法来快速编写和运行程序。即使只想把数据块保存到磁盘中,并且根本不需要使用对象,也可以使用NSData来简化工作。只需要将数据包装在一个NSData对象中,然后再NSData对象上调用writeToFile: atomically:方法。
这些函数的一个缺点就是,它们不会返回任何错误信息。如果不能加载文件,只能从方法中得到nil指针,而不能确定出现了何种错误。
创建工程
在Xcode中,使用Single View Application模板创建一个项目,命名Persistence,点击Main.storyboard,布局如下图

连线,添加处理函数:
1 | @interface PlistViewController () |
1 | - (void)viewDidLoad { |
四、归档
在Cocoa世界中,归档是指另一中形式的序列化,但它是任何对象都可以实现的更常规的类型。专门编写用于保存数据的任何模型对象都应该支持归档。使用对模型对象进行归档的技术可以轻松将复杂的对象写入文件,然后再从中读取它们。
只要在类中实现的每个属性都是标量(如整型或浮点型)或都是遵循NSCoding协议的某个类的实例,就可以对整个对象进行完全的归档。由于大多数支持存储数据的Foundation和Cocoa Touch类都遵循NSCoding协议(不过,有一些例外,如UIImage),对于大多数类来说,归档相对而言比较容易实现。
尽管对归档的使用没有严格要求,但还有一个协议应该与NSCoding一起实现,即NSCopying协议。后者允许复制对象,这使开发者在使用数据模型对象时具备了较大的灵活性。
遵循NSCoding协议
NSCoding协议声明了两个必须实现的方法,一个方法将对象编码到归档中,另一个方法对归档解码来创建一个新对象。这两个方法都传递一个NSCoder实例,使用方式与NSUserDefaults非常相似。也可以使用KVC对对象和原生数据类型进行编码和解码。
1 | @protocolNSCoding |
当对象需要保存自身时,encodeWithCoder:方法将被调用;当对象需要加载自身时,initWithCoder:方法将被调用。
那么,这个编码器是什么呢?NSCoder是一个抽象类,定义一些有用的方法来在对象与NSData之间来回转换。完全不需要创建新NSCoder,因为它实际上并无多大作用。但是,我们实际上要使用NSCoder的一些具体的子类来编码和解码对象。我们将使用其中两个子类NSKeyedArchiver和NSKeyedUnarchiver。
initWithCoder:和其他任何init方法一样,在对对象执行操作之前,需要使用超类对它们进行初始化。为此,可以采用两种方式,具体取决于父类。如果父类采用NSCoding协议,则应该调用[super initWithCoder:decoder];否则,只需要调用[super init]即可。NSObject不采用NSCoding协议,因此我们使用简单的init方法。
+ archivedDataWithRootObject:类方法编码thing对象。首先,它在后台创建一个NSKeyedArchiver实例;然后,它将NSKeyedArchiver实例传递给对象thing的-encodeWithCoder:方法。当thing编码自身的属性时,它可能对其他对象也进行编码,例如,字符串、数组以及我们可能输入到该数组中的任何内容。整个对象集合完成键和值的编码后,具有键/值对的归档程序将所有对象扁平化为一个NSData类并将其返回。
如果愿意,可以使用-writeToFile:atomically:方法将这个NSData类保存到磁盘中。在此,我们先处理thing对象,然后通过freezeDried表示法重新创建它,并将它输出:
1 | thing =[NSKeyedUnarchiveObjectWithData: freezeDried]; |
如果被编码的数据中含有循环将会怎么样?例如,如果thing包含在自身的subThingies数组中会怎样?thing会对数组进行编码吗?哪个对象对thing进行编码,哪个对象对数组进行编码,哪个对象再次对thing进行编码,依此类推?幸运的是,Cocoa在归档程序和解压程序实现上非常灵活,能够保存并恢复对象周期。
实现NSCopying协议
遵循NSCopying对于任何数据模型对象来说都是非常好的事情。NSCopying有一个copyWithZone:方法,可用来复制对象。实现NSCopying与实现initWithCoder:非常相似,只需要创建一个同一类的新实例,然后将新实例的所有属性都设置为与该对象属性相同的值即可。
说明:不要过于担心NSZone参数。它指向系统用于管理内存的struct。只有在极少数情况下,开发者才需要关注zone或者创建自己的zone。目前,还没有使用多个zone的说法。对某个对象调用copy的方法与使用默认zone调用copyWithZone的方法完全相同,几乎始终能满足你的需求。事实上,现在的iOS上完全可以忽略zone。NSCopying用zone在本质上是考虑向后兼容性所致。
创建工程
按照上文创建工程,设计界面(与上文界面相同),连线,添加响应方法:
1 | #import "ArchiverViewController.h" |
1 | - (void)viewDidLoad { |
与属性列表序列化实现多几行代码,那么是否就是使用归档比使用序列化属性列表更有优势呢?答案是否定的。如果我们拥有一个包含可归档对象的数组,则可以对数组实例本身进行归档来归档整个数组。对集合类(如数组)进行归档时,也会归档其包含的所有对象。只要放入数组或字典中的对象遵循NSCoding,就可以归档数组或字典并还原它。这样,对其进行归档时,其中所有对象都将位于已还原的数组和字典中。这一点并不适用于属性链接的持久化,它只支持一小部分的Foundation对象类型。如果没有编写额外的代码,来将这些自定义类的实例与字典通过每个对象属性的键进行互相转化,就不能对其进行持久化。
换句话说,NSCoding方法具有非常好的伸缩性,因为无论添加多少对象,将这些对象写入磁盘的方式都完全相同。不过使用属性列表的话,工作量会随着添加对象而增加。
五、SQLite3
SQLite3在存储和检索大量数据方面非常有效。它能够对数据进行复杂的聚合,与使用对象执行这些操作相比,获得结果的速度更快。
SQLite3使用SQL(Structured Query Language,结构化查询语言),SQL是与关系数据库交互的标准语言。
这里推荐两篇SQLite3深入研究探索的参考文章:
An Introduction to the SQLite3 C/C++ Interface (www.sqlite.org/cintro.html)
SQL As Understood by SQLite (www.sqlite.org/lang.html)
关系数据库(包括SQLite3)和面向对象的编程语言使用完全不同的方法来存储和组织数据。这些方法差异很大,因而出现了在两者之间进行转换的各种技术以及很多库和工具。这些技术统称为ORM(Object-Relational-Mapping,对象关系映射)。目前有很多种ORM工具可用于Cocoa Touch。
绑定变量
虽然可以通过创建SQL字符串来插入值,但常用的方法是使用绑定变量来执行数据库插入操作。正确处理字符串并确保它们没有无效字符(以及引号处理过的属性)是非常烦琐的事情。借助绑定变量,这些问题将迎刃而解。
要使用绑定变量插入值,只需要按正常方式创建SQL语句即可,不过要在SQL字符串中添加一个问号。每个问号都表示一个需要在语句执行之前进行绑定的变量。然后,准备好SQL语句,将值绑定到各个变量并执行命令。
1 | /*将整型数据绑定到第一个变量,将字符串绑定到第二个变量,然后执行并结束语句*/ |
根据希望使用的数据类型,可以选择不同的绑定语句。大部分绑定函数都只有3个参数。
1)无论针对哪种数据类型,任何绑定函数的第一个参数都指向之前在sqlite3_prepare_v2()调用中使用的sqlite3_stmt。
2)第二个参数是被绑定变量的索引。它是一个有序索引值,者这表示SQL语句中的第一个问号是索引1,其后面的每个问号都依次按序增加1。
3)第三个参数始终表示应该替换问号的值。
有些绑定函数(比如用于绑定文本和二进制数据的绑定函数)拥有另外两个参数。
1)一个参数是在上面第三个参数中传递的数据长度。对于C字符串,可以传递-1来代替字符串长度,这样函数将使用整个字符串。对于所有其他情况,需要指定所传递数据的长度。
2)另外一个参数是可选的函数回调,用于在语句执行后完成内存清理工作。通常,这种函数使用malloc()释放已分配的内存。
创建工程
创建工程,设计布局,与前文工程相同操作,连线,添加响应方法:
1 | #import "SqliteViewController.h" |
导入sqlite库
1 | - (void)viewDidLoad { |
其实,以上者三种方式没有什么差异,只不过是三种不同的持久化机制而已。
六、Core Data
Core Data是一款稳定、功能全面的持久化工具。
术语
实体:表示对对象的描述。
托管对象:表示在运行时创建该实体的具体实例。
注意,在数据模型编辑器中,你将创建实体;而在代码中,你将创建并检索托管对象。实体和托管对象之间的差异类似于类与类的实例。
实体由属性组成,属性分为3种类型:
1)特性(attribute):特性在Core Data实体中的作用与实例变量在Objective-C类中的作用完全相同,它们都用于保存数据。
2)关系(relationship):关系用于定义实体之间的关系。举例来说,假设要定义一个Person实体,你可能首先会定义一些特性,比如height和weight,还可以定义地址特性,比如state和zipCode,或者将它们嵌入到单独的HomeAddr实体中。使用后面这种方法,你可能希望在Person与HomeAddr之间创建一个关系。关系可以是一对一或一对多。从Person到HomeAddr的关系可以是“一对一”,因为大多数人都只有一个家庭地址。从HomeAddr到Person的关系则可以是“一对多”,因为可能多个人住在同一个家庭地址。
3)提取属性(fetched property):提取属性是关系的备选方法。用提取属性可以创建一个能在提取时被评估的查询,从而确定哪些对象属于这个关系。沿用刚才的例子,一个Person对象可以拥有一个名为Neighbors的提取属性,该属性查找数据存储中与这个Person的HomeAddr拥有相同zipCode的所有HomeAddr对象。由于提取属性的结构和使用方式,它们通常都是一对一关系。提取属性也是唯一一种能够让你跨越多个数据存储的关系。
创建工程
依旧如前文方式创建工程,添加响应参数,不过在这里要注意的是,Core Data的创建方法步骤:
1)创建Model文件
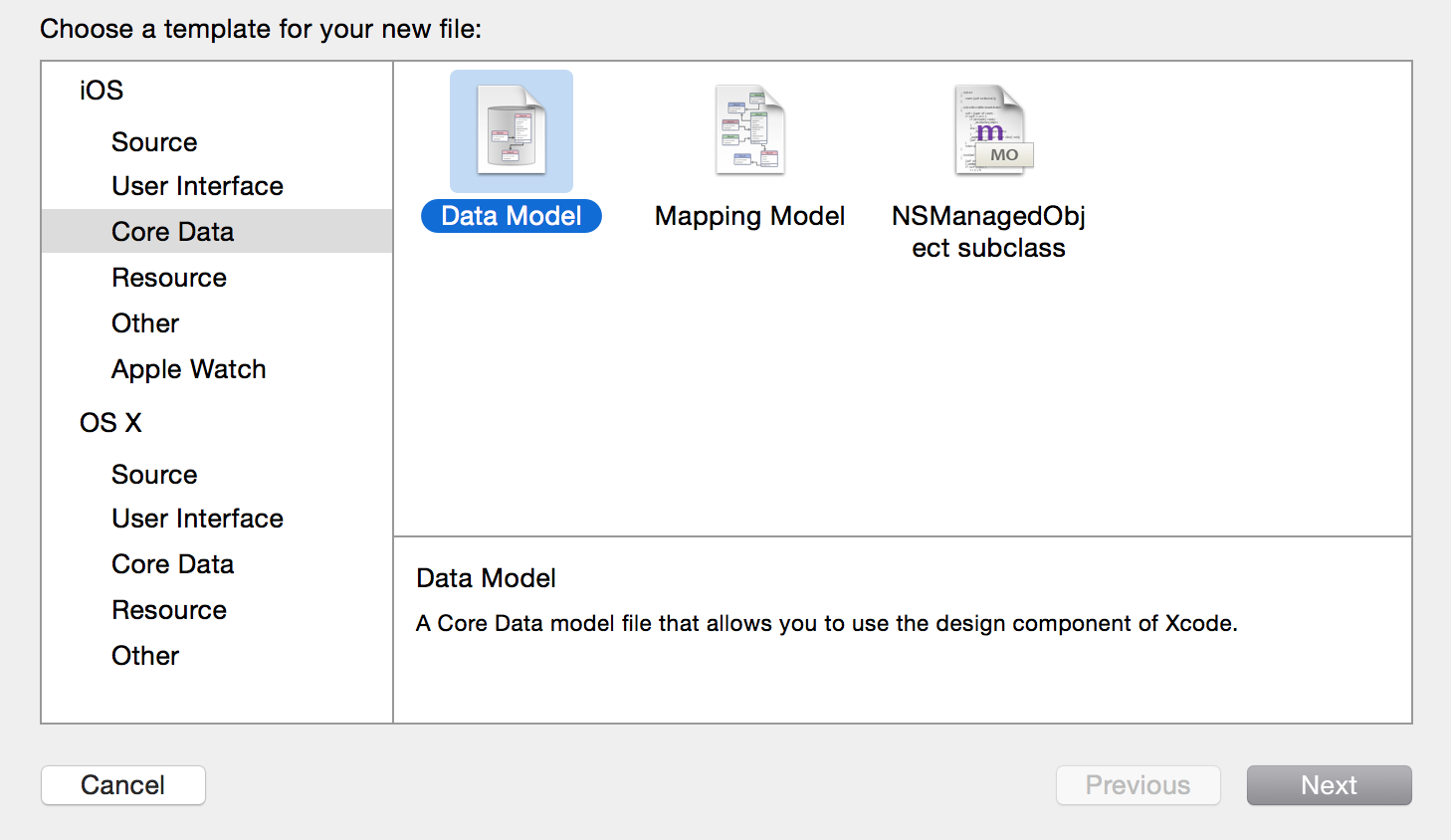
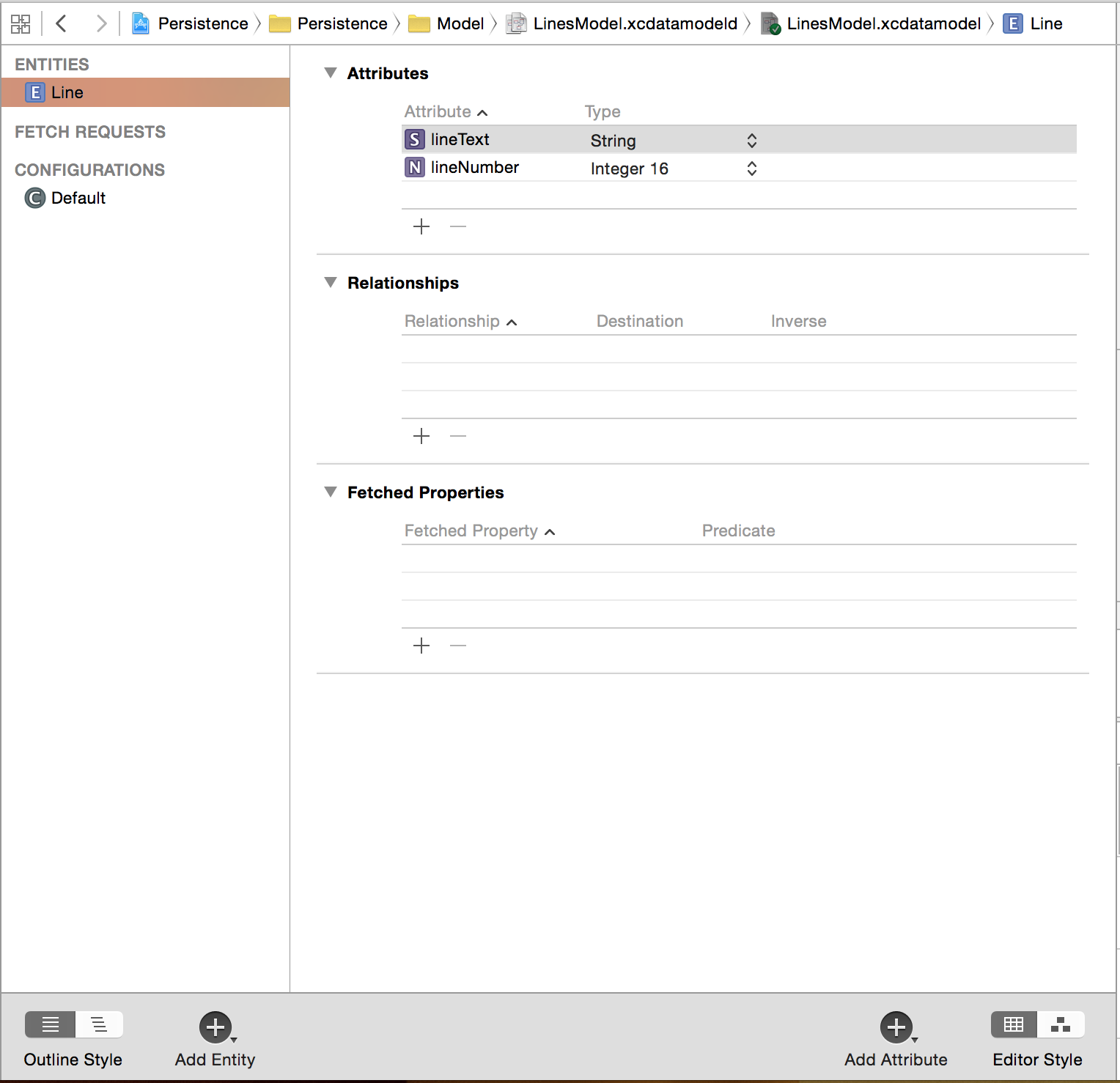
2)编辑Model文件,点击“Add Entity”添加实体,点击“Add Attribute”添加特性
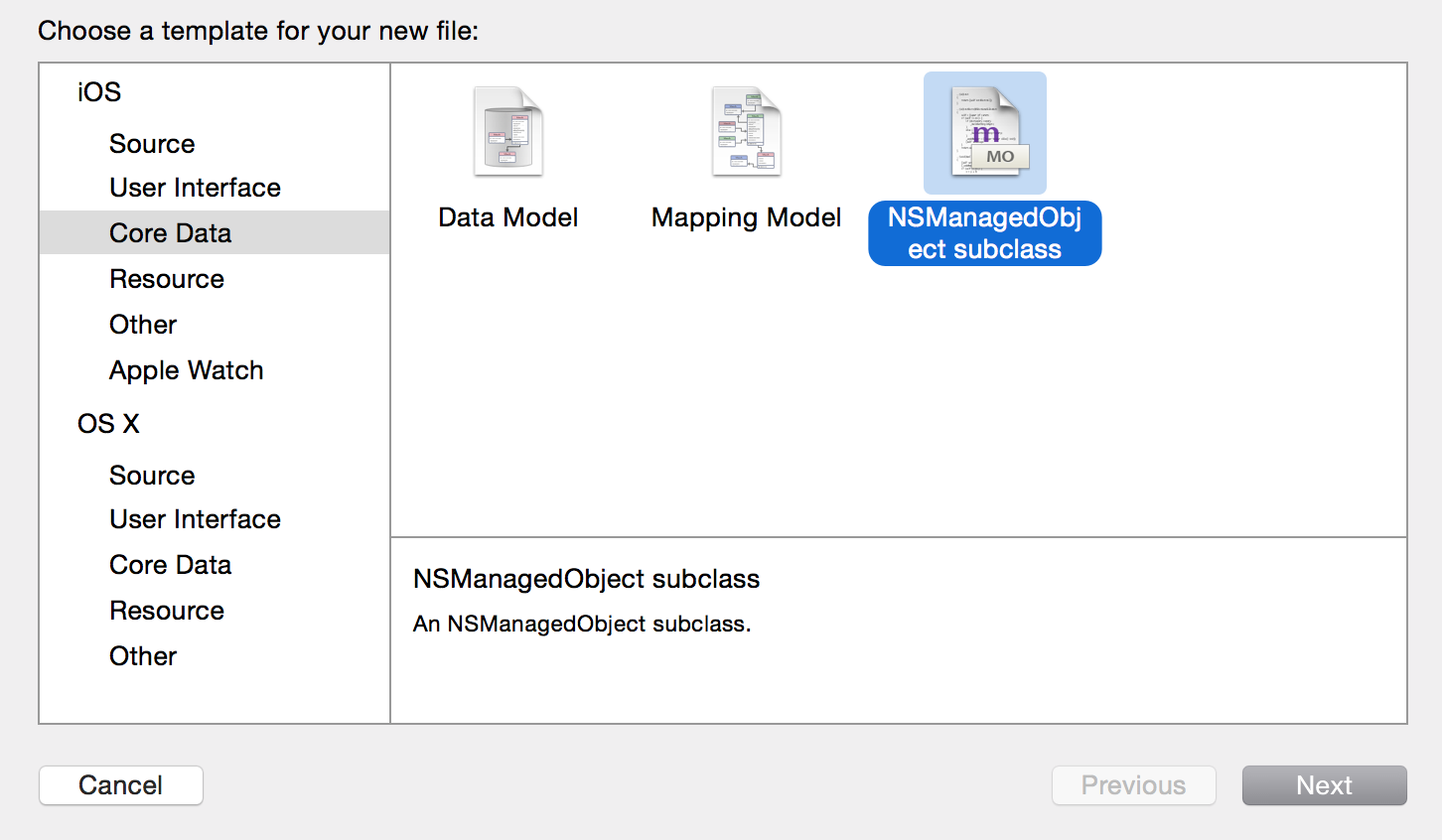
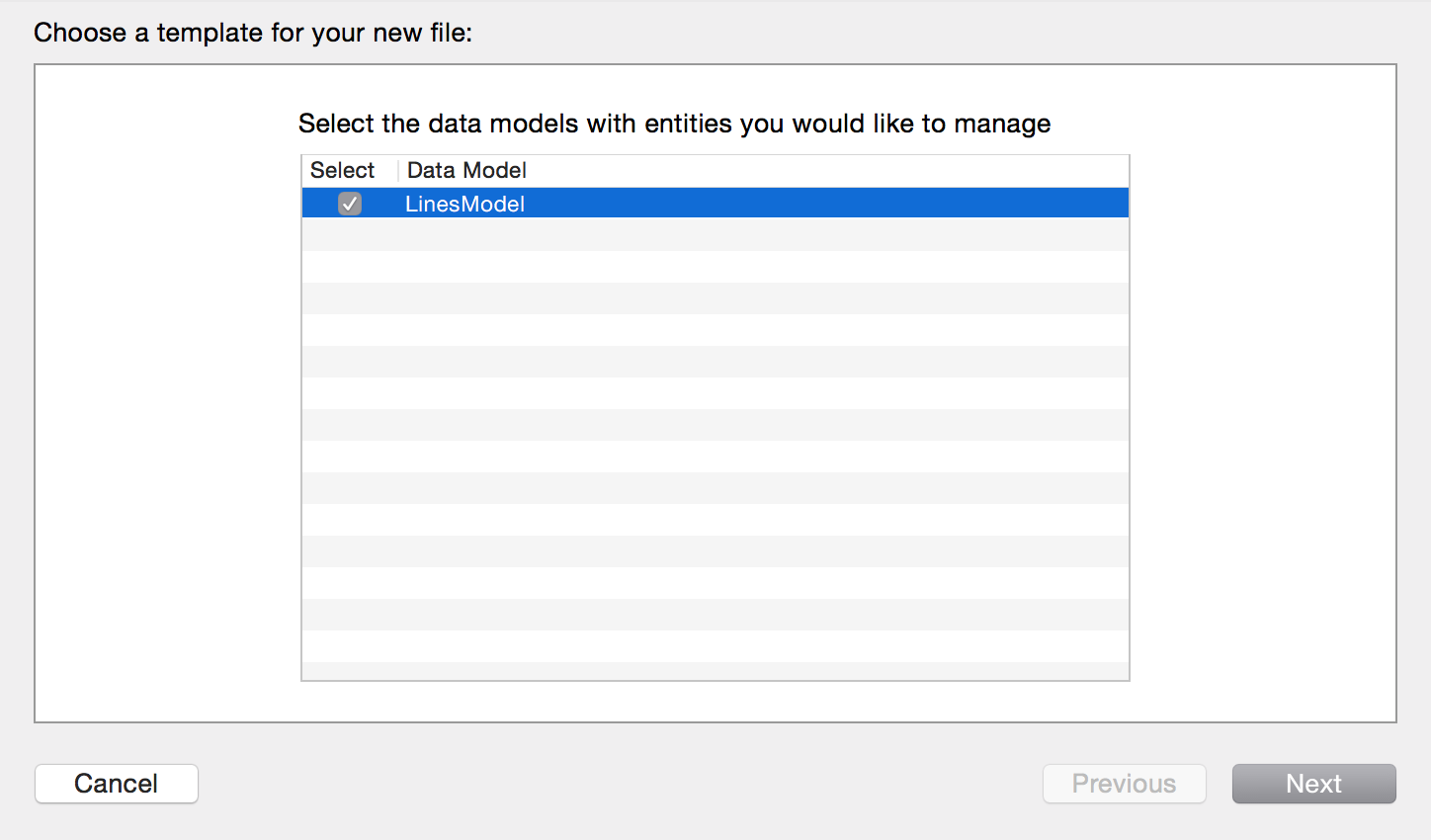
3)创建NSManagedObject文件,关联数据模型
1 | #import "CoreDataViewController.h" |
1 | - (void)viewDidLoad { |
Core Data版本与之前的版本功能完全相同。Core Data需要的工作量很大。对于这种简单的应用,它并没有提供明显的优势。但是在比较复杂的应用中,Core Data可以显著减少设计和编写数据模型所需的时间。
七、总结
四种数据持久化机制,各有优势,根据使用情况选择对应机制进行数据持久化。