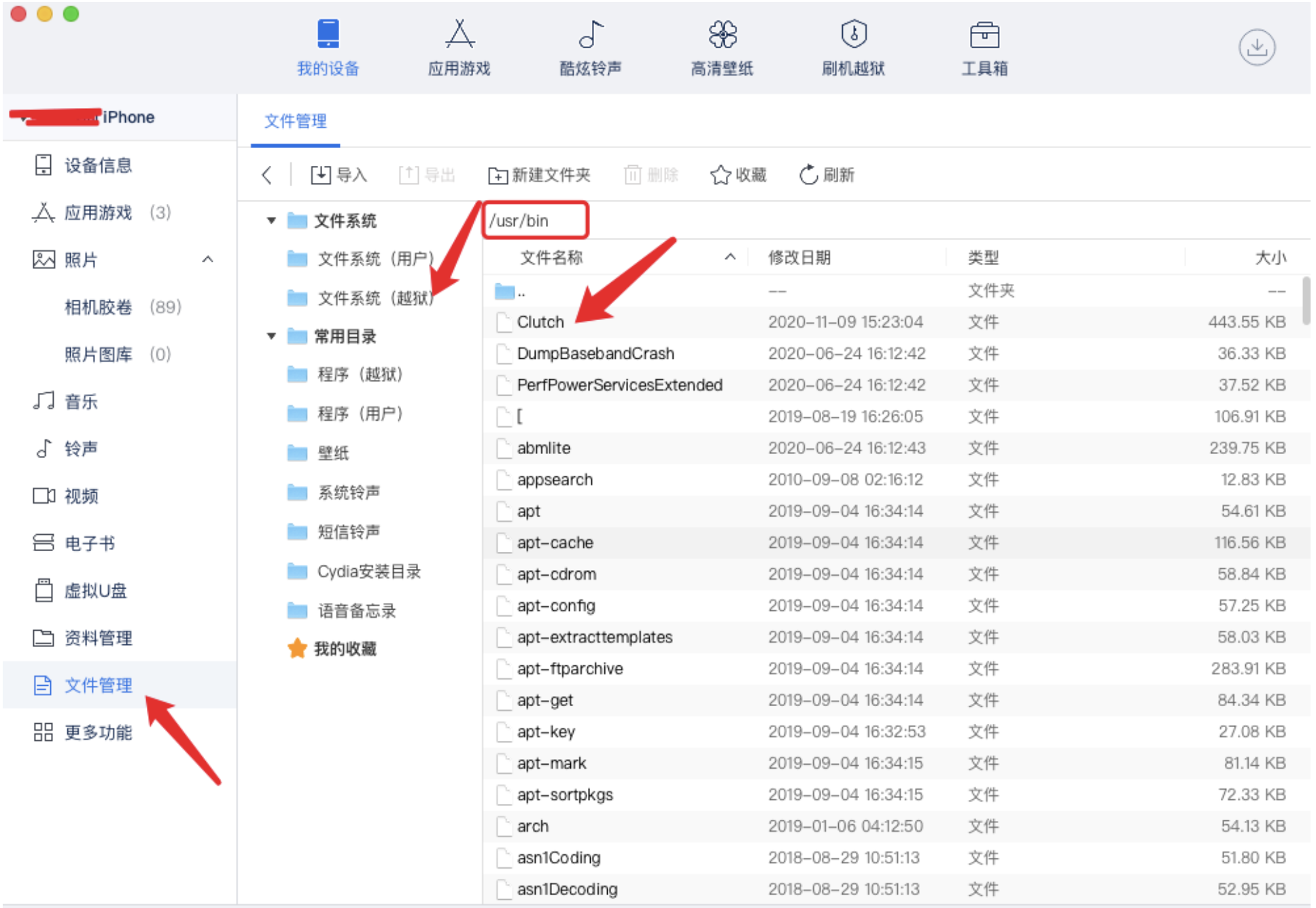
随着网络技术的发展,接入网络的设备的种类越来越多,配置越来越复杂,来自不同设备厂商的设备也往往会增加自己特有的功能,这就导致在一个网络中往往会有很多具有不同特性的、来自不同厂商的设备,为了方便对这样的网络进行管理,就需要使得不同厂商的设备能够在网络中相互发现并交互各自的系统及配置信息。 LLDP(Link Layer Discovery Protocol,链路层发现协议)就是用于这个目的的协议。LLDP 定义在 802.1ab 中,它是一个二层协议,它提供了一种标准的链路层发现方式。LLDP 协议使得接入网络的一台设备可以将其主要的能力,管理地址,设备标识,接口标识等信息发送给接入同一个局域网络的其它设备。当一个设备从网络中接收到其它设备的这些信息时,它就将这些信息以MIB的形式存储起来。
这些 MIB 信息可用于发现设备的物理拓扑结构以及管理配置信息。需要注意的是 LLDP 仅仅被设计用于进行信息通告,它被用于通告一个设备的信息并可以获得其它设备的信息,进而得到相关的 MIB 信息。它不是一个配置、控制协议,无法通过该协议对远端设备进行配置,它只是提供了关于网络拓扑以及管理配置的信息,这些信息可以被用于管理、配置的目的,如何用取决于信息的使用者。
结构
LLDP 的框架结构如图所示
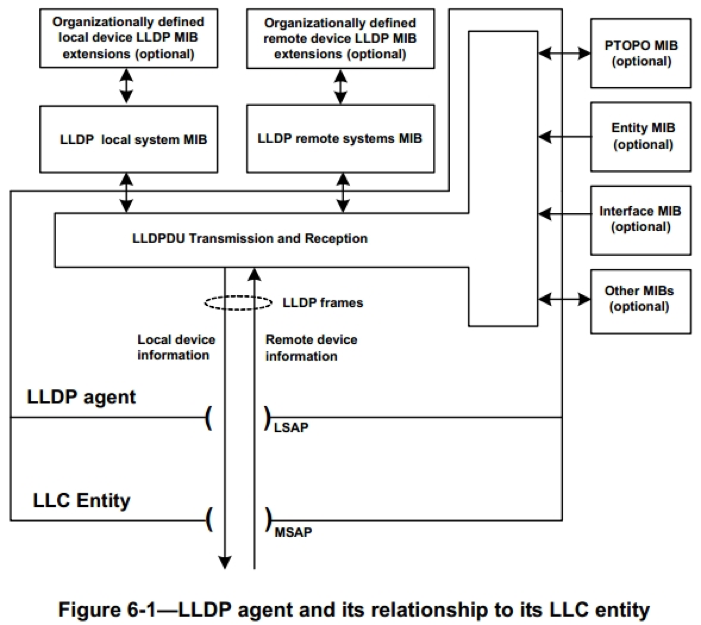
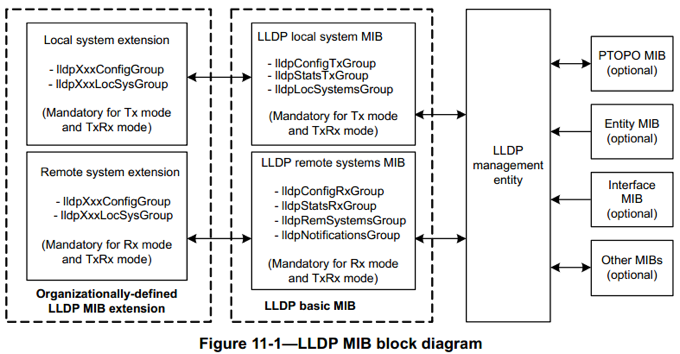
此图也表明 LLDP 就是一个信息发现与通告协议,LLDP 的实体主要维护了两个 MIB 库,一个 local system MIB,一个 remote system MIB。从其名字也可以看出,一个用于维护本地相关的设备 MIB 信息,一个用于维护远端设备 MIB 信息。
LLDP 通过与上图中右侧的几个 MIB 库交互来初始化并维护 local system MIB,并将本地的相关信息通告出去;同时当接收到来自其它设备的信息时就将其更新到remote system MIB 中。通过这种工作方式,一个设备就可以将自己的信息通告出去并获得网络中其它设备的相关信息,最终获得反应网络拓扑以及其它配置信息的两个 MIB 库。这两个库可以被其用户用来完成各种功能。需要说明的是LLDP 信息的通告以及接收处理不受端口的STP状态的影响。
基本概念
帧格式
封装有 LLDPDU 的报文称为 LLDP 帧,其封装格式有两种:Ethernet II 和 SNAP(Subnetwork Access Protocol,子网访问协议)。
Ethernet II 格式封装的 LLDP 帧
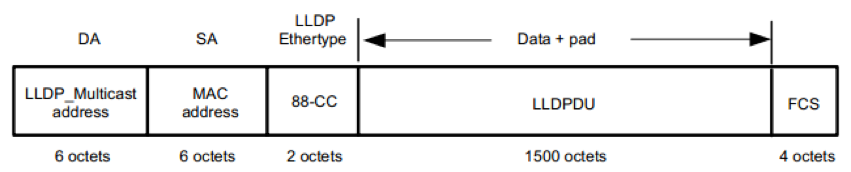
上图是以 Ethernet II 格式封装的 LLDP 帧,其中各字段的含义如下:
- DA:目的 MAC 地址,为固定的组播 MAC 地址 0x0180-C200-000E。
- SA:源 MAC 地址,为端口 MAC 地址或设备 MAC 地址(如有端口地址则用端口 MAC 地址,否则用设备 MAC 地址)。 指与设备相邻连接设备的桥 MAC。
- LLDP Ethertype:帧类型,为 0x88CC。
- LLDPDU:LLDP Data Unit,LLDP 数据单元,它是 LLDP 信息交换的主体。
- FCS:帧检验序列。
SNAP 格式封装的 LLDP 帧
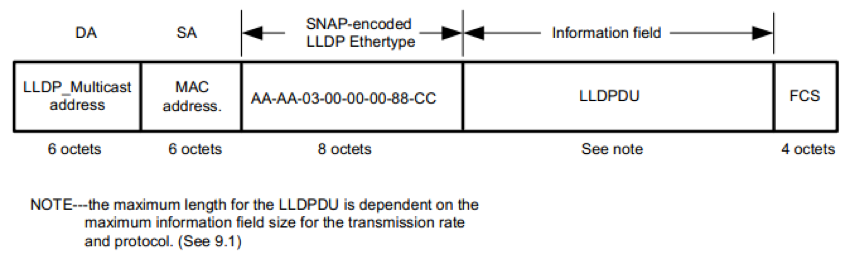
上图是以 SNAP 格式封装的 LLDP 帧,其中各字段的含义如下:
- DA:目的 MAC 地址,为固定的组播 MAC 地址 01-80-C2-00-00-0E。
- SA:源 MAC 地址,为端口 MAC 地址或设备 MAC 地址(如有端口地址则用端口 MAC 地址,否则用设备 MAC 地址)。
- Type:帧类型,为 0xAAAA-0300-0000-88CC。
- Data:数据,为 LLDPDU。
- FCS:帧检验序列。
目的地址
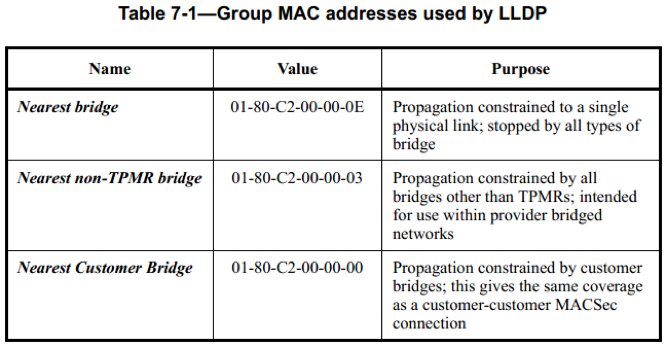
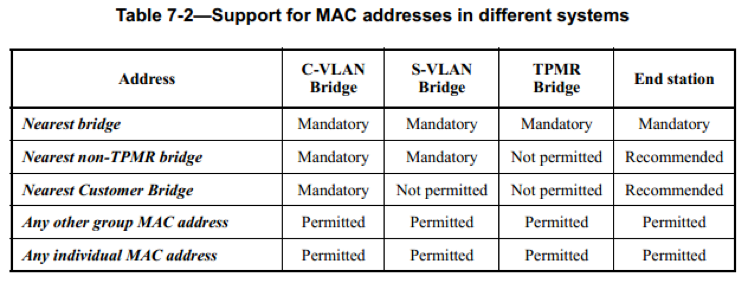
目的地址实际上包括三个,分别为 01-80-C2-00-00-0E,01-80-C2-00-00-03,01-80-C2-00-00-00。这三个地址分别用于不同的目的,它们可以跨越不同的网络。
- 01-80-C2-00-00-0E,也被称为 Nearest Bridge 组地址:无论是 Two-Port MAC Relay (TPMR)组件、S-VLAN 组件、C-VLAN 组件,还是 802.1D 网桥都不能转发目的为该地址的帧。简单的说任何类型的网桥都不能转发目的为该地址的帧,目的为该地址的帧被限制在连接两个网桥接口的连接上传输。
- 01-80-C2-00-00-03,也被称为 Nearest non-TPMR Bridge 组地址:对于目的地址为该地址的帧,Two-Port MAC Relay (TPMR)组件将成为一个中继器,即不接收它。而 S-VLAN(Service Provider VLAN)组件,C-VLAN(Customer VLAN)组件,以及 802.1D 网桥都不能转发它,而是需要进行接收并处理。因此目的地址为该地址的帧将跨越 TPMR。
- 01-80-C2-00-00-00,也被称为 Nearest Customer Bridge 组地址:对于目的地址为该地址的帧,Two-Port MAC Relay (TPMR)组件以及 S-VLAN 组件将成为中继器,即不接收它。而 C-VLAN 组件,以及 802.1D 网桥都不能转发它,而是需要进行接收并处理。因此目的地址为该地址的帧将跨越 TPMR 以及 S-VLAN。
TPMR 介绍
TPMR 以及 S-VLAN,C-VLAN 都是 802.1Q 中的概念,包括这三者的网络以及各个地址的作用范围如下图所示
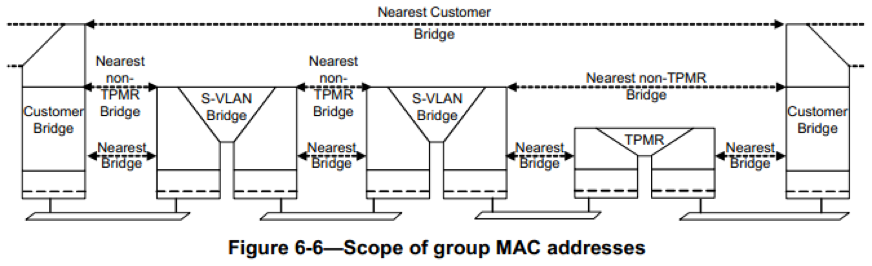
- C-VLAN:Customer VLAN,是用户网络内部使用的 VLAN;
- S-VLAN:Service VLAN,服务提供商网络中使用的 VLAN,该 VLAN 标识 VPN 用户或者是用户的业务;
- Customer Bridge: Customer 网络中的 Bridge,只能识别 C-VLAN;
- Provider Bridge:服务提供商网络中的 Bridge,根据处理内容的不同又分为S-VLAN Bridge 和 Provider Edge Bridge。其中 S-VLAN Bridge 只能识别 S-VLAN; Provider Edge Bridge 可以同时识别 C-VLAN 和 S-VLAN;
- C-VLAN Component:在 Bridge 内可识别、插入、删除 C-VLAN 的实体,每个端口一个,对 C-VLAN 的操作互相独立(两个端口上接收到相同的 C-VLAN,但由于属于不同的客户最后的处理结果会不同);
- S-VLAN Component:在 Bridge 内可识别、插入、删除 S-VLAN 的实体,由于在一个 Bridge 内不存在相同的 S-VLAN 属于不同服务提供商的情况,因此在一个桥内只有一个 S-VLAN 的实体。
QinQ 介绍
QinQ 的理论基础,是 IEEE 定义的 802.1ad。在这个规范里面,IEEE 提出了一个概念,它认为汇聚和接入层那里有这么两种设备:S-VLAN Bridge 和 Provider Edge Bridge,再往下就是 Customer System 了(注意,这里说 System 而不是 Bridge,是因为 Customer 接进来的未必是二层设备,可能也是三层设备)。VLAN 空间也被分成两个 VLAN 空间,即 S-VLAN 和 C-VLAN,S 即 Service Provider,C 即 Customer。在 S-VLAN Bridge 上,只有 S-VLAN 空间,而在 Provider Edge Bridge 上,则既有 S-VLAN 空间,又有 C-VLAN 空间。相应的,这个 Bridge 就被从逻辑上划分为两部分,支持 S-VLAN 功能的部分称之为 S-VLAN Component,支持 C-VLAN 功能的部分称之为 C-VLAN Component。S-VLAN Bridge 只包含 S-VLAN Component。
除了两种 Bridge 的概念,802.1ad 还提出了三种 Service 类型和四种 Port 类型,其中一种 Port 是内部 Port,对用户不可见,其它三种 Port 分别对应了三种不同的 Service,即运营商可以通过在交换机上配置三种不同的 Port 类型,来相应的为用户提供三种不同类型的 Service。三种 Service 分别是 Port Based Service,C-Tag Based Service 和 S-Tag Based Service。四种Port 分别是 Customer Network Port (CN), Customer Edge Port(CE),Provider Network Port(PN),Provider Edge Port(内部 Port)。
所谓 Port Based Service,就是说某个 Service 是基于 Port 的,从该 Port 进来的所有报文,都被认为是属于某一个特定的 Customer 的,不管它是否带 C-Tag,带了什么样的 C-Tag,这些信息统统被忽视。所有从这个 Port 进来的报文被赋予一个 S-VLAN,该 S-VLAN 被用来标识该 Customer,或说该 Service。提供这种 Service 的 Port 就是CN Port。CN Port 的实质就是运营商为一个 Customer 提供一个专门的 Port,不跟别的 Customer 共享。注意,从这个 Port 上进来的报文不能带 S-Tag,否则会被丢弃。也就是说,对于 S-Tag 而言,这个 Port 是 Access Port,而不是 Trunk Port。这是跟后面的 S-Tag Based service 本质的不同。
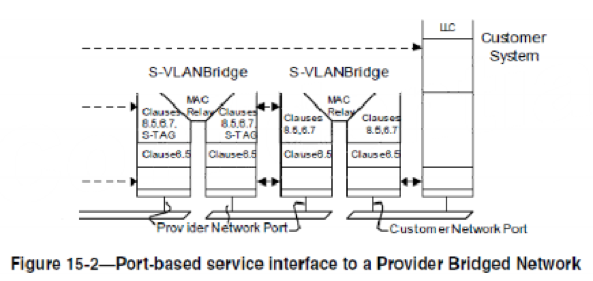
所谓的 S-Tag Based Service,就是说从一个 Port 上进来的报文,根据 S-VLAN 来把它们划分到不同的 Customer,换句话说,是用 S-VLAN 来标记 Customer。提供这种 Service 的 Port 也是 CN Port,只不过这个时候的 CN Port,必须配置成 Trunk Port,只识别 S-VLAN,根据 S-VLAN 来标识 Customer,转发报文。
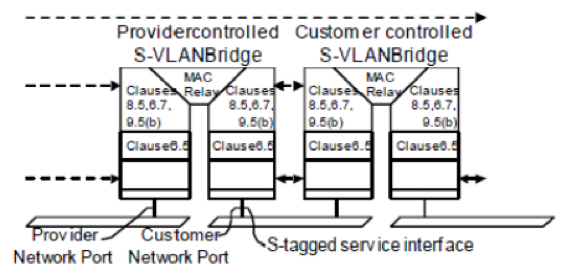
所谓的 C-Tag Based Service,就是指报文携带 C-Tag 进入 Port,在该 Port 上基于 C-VLAN 来标识 Customer,一个 Port 上可以支持多个 Customer。用来支持 C-Tag Based Service 的 Port 就是 CE Port,CE Port 是 C-VLAN Component 的一部分,对于 C-VLAN 而言,CE Port 是 Trunk Port。它不识别 S-Tag。
PN Port 是 S-VLAN Component 的一部分,它跟 CN Port 唯一的不同是 CN Port 面向 Customer Network,而它面向 Provider Network,在实际的交换机中通常被配置成 Uplink Port,而且通常都是 VLAN Trunk Mode(相对于 Access Mode)。
对于一个拥有 S-VLAN Component 和 C-VLAN Component 的 Provider Edge Bridge 而言,在做 Mac Forwarding/Learning 的时候,有两种模式,一种是用 S-VLAN+MAC,另外一种则是 S-VLAN+C-VLAN+MAC,前者即所谓的 C-VLAN Unaware Mode,而后者则是 C-VLAN Aware Mode。
C-VLAN Aware Mode 带来的好处是显而易见的,因为它将 VLAN 空间从 4K 扩展到了 16M,但是它的问题在于,当前绝大多数芯片都不支持,就算支持了,也不太可能支持到理论上的 16M。
一种独创的 QinQ 模式
现实世界中用户的需求是千奇百怪,有一种需求,是市场上现存的交换机所解决不了的。在讨论这种需求之前,先看一下当前交换机的做法。无论各个厂家的实现差别有多大,但是有一点大家都是一样的,就是在接入交换机上,通过 Port 或者 C-VLAN 来识别用户,然后为每个用户分配一个 S-VLAN,然后用 S-VLAN 来做后续处理,如 ACL/QoS/Mac Learning/Mac Forwarding 等。
但是运营商,特别是欧美的一些运营商可能有这样的需求,为了描述的方便,我们假设有个运营商 A,它在为它的客户提供服务的时候,有的时候需要租用别的运营商,假设是运营商 B 的网络,在租用网络的时候,A 这些 B 的客户,运营商 B 需要给 A 分配 S-VLAN,而且往往是一个 S-VLAN 多少钱,因为 VLAN 是稀缺资源,特别是网络比较大的时候。这个时候,如果运营商 A 为它自己的客户每个都分配一个 S-VLAN,那么相应的它就需要向 B 也申请很多个 S-VLAN,不划算,这个时候它就想在自己的接入设备上,不用 S-VLAN 来标识 Customer,给所有的 Customer 分配同一个 S-VLAN,用该 S-VLAN 来穿越 B 的网络,这个时候,S-VLAN 的意义不是代表 Customer,而是代表一个 Tunnel。
问题关键在于,如果不用 S-VLAN 来代表 Customer,在 A 的接入设备上,如何来对不同的 Customer 来做区分处理呢?用 C-VLAN 肯定是不行的,因为不同 Port 上的 C-VLAN 代表的 Customer 可能是不同的。Centec 的交换机,在芯片内部用一个不同于 C-VLAN 和 S-VLAN 的 CustomerID 来标识 Customer,用这个值来做后续的一系列 Customer 的处理,非常强大。
QinQ 的不足
尽管 QinQ 貌似很好很强大,并且受到热烈追捧,但是这不能掩盖它的先天不足。
QinQ 的最大不足就是它无法对运营商网络完全隐藏 Customer 信息,因为它可以让运营商 Core Network 的设备看不到 Customer VLAN,但是无法让它们看不到 Customer MAC。而这一点有两个不利的影响,一个是 Scalability 非常差,如果中间的设备都是二层设备,会导致 MAC 表非常大;第二个不利的影响则是,一旦 Customer 网络出现了环路,会导致 Provider Network 里面的设备不断进行 MAC Learning,万一有 ARP 之类报文,还可能冲击 CPU。
如果 Customer VLAN 对运营商网络不可见,那么就起不到扩展 VLAN 空间的作用,运营商的 VLAN 空间就仍然只有 4K。
而 PBB,即所谓的 MAC-in-MAC 则能很好的解决 QinQ 的这个不足,因为 PBB 不仅在原来的报文上新增一个 VLAN,还新增 MACSa/MACDa 以及 24 个 bit 的 Isid(用来标识 Service),它可以完全对运营商的 Core Network 设备隐藏 Customer 信息,且能利用 Isid 来支持 16M Customer/Service。
当然PBB也有PBB的问题,目前看不到它有成为主流技术的趋势。
LLDPDU
LLDPDU 是 LLDP 的有效负载,用于承载要发送的消息。LLDPDU 的格式如下图所示

LLDPDU 采用了 TLV 的格式,即 type+length+value 的格式,type 表示 TLV 的类型,length 是以字节为单位的 TLV 的长度,value 是该 TLV 的值。其中 Chassis ID TLV,Port ID TLV Time To Live TLV 以及 End Of LLDPDU TLV 是强制的,必须包含的部分,除此之外在 TLV Time To Live TLV 和 End Of LLDPDU TLV 之间可以包含 0 个到多个可选的其它 TLV。
TLV
TLV 是组成 LLDPDU 的单元,每个 TLV 都代表一个信息。LLDPDU 的 TLV 可以分为两大类
- 被认为是网络管理的基础的 TLV 集合,所有的 LLDP 实现都需要支持。
- 组织定义的 TLV 扩展集合,包括
802.1 组织定义 TLV、802.3 组织定义 TLV 以及其他组织定义的 TLV。这些 TLV 用于增强对网络设备的管理,可根据实际需要选择是否在 LLDPDU 中发送。
TLV 的基本格式如图所示

TLV的类型域的定义及分配如下图所示
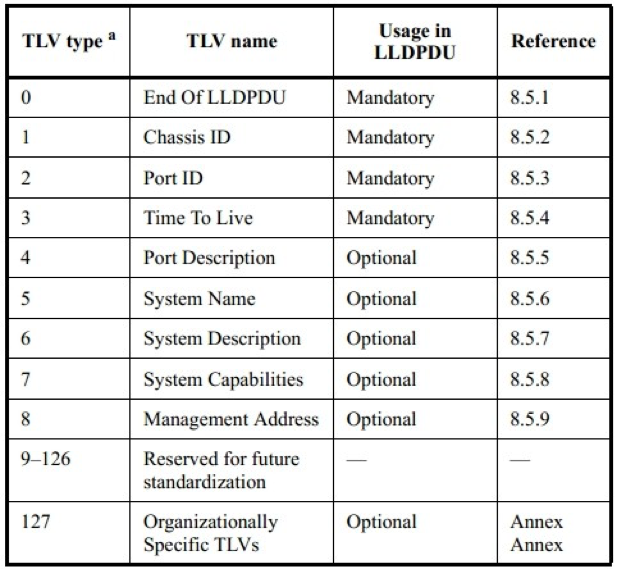
其中 type0-8 属于基本的 TLV 集合。对于其中的 Mandatory 的 TLV,它是必须包含在 LLDP 中的。
组织定义 TLV 集合的格式如下图所示
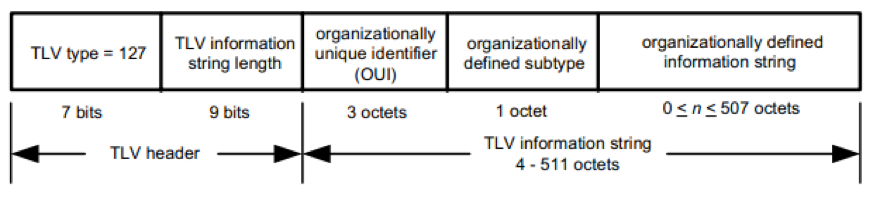
其中
- OUI:组织机构的 ID。
- organizationally defined subtype:组织自定义的类型。
- organizationally defined information string:传输的信息。
基础 TLV 集合
几个强制的必须包含的 TLV 的定义如下。非强制的可以参考 IEEE802.1AB。
End Of LLDPDU TLV
该 TLV 用于标识 LLDPDU 的结束。其格式如下
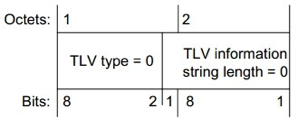
由于 length=0,因此它不包含 value 域。
Chassis ID TLV
该 TLV 用于通告该 LLDPDU 发送者的 Chassis ID。由于有很多方式可用来标识一个 Chassis,因此在该类 TLV 中包含一个子类型域用于告诉接收者,发送者的 Chassis ID 采用的是哪一种标识方式。其格式如图所示
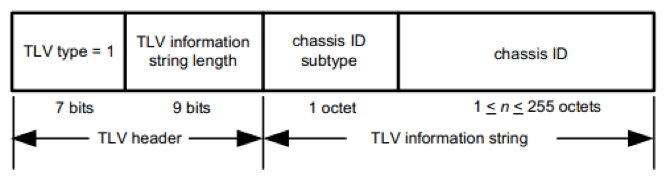
每个 LLDPDU 必须包含且仅包含一个该类型的 TLV。由于 Chassis ID 实际上是用于标识设备的,因此在连接可用时它应该保持不变。
Chassis 子类型所可能的取值如图所示
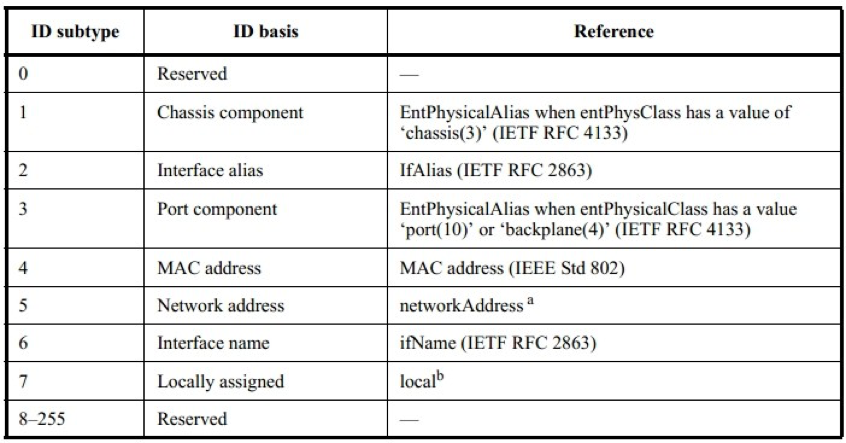
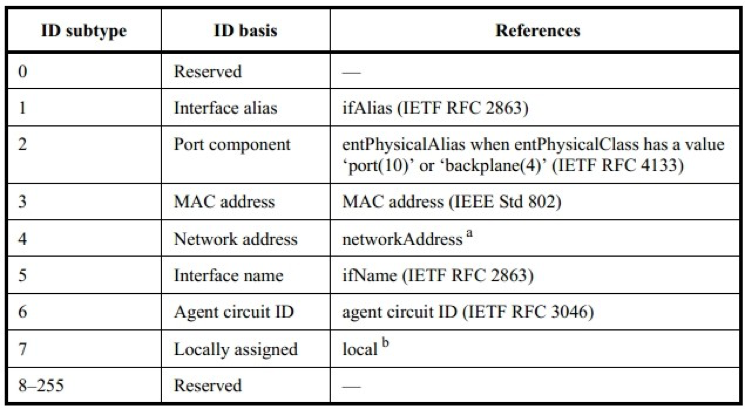
Port ID TLV
它用于标识发送该 LLDPDU 的设备的端口。类似于 Chassis ID,有很多方式可以标识一个 Port,因此该 TLV 也包含一个子类型域。其格式如下图所示
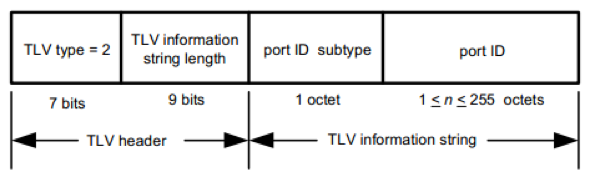
每个 LLDPDU 必须包含一个且只能包含一个该类型的 TLV。同时,当端口可用时,从该端口发送出去的 LLDPDU 的该 TLV 应该保持不变。
其子类型的可能取值如下图所示
Time To Live TLV
该 TLV 用于告诉接收端,它接收到的这些信息的有效期有多长。其格式如图所示
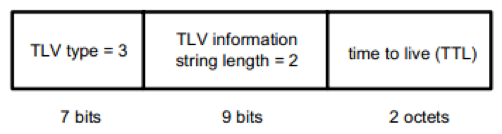
TTL 的时间单位是秒,由于只有 2 个字节长,因而最大有效时间是 65536 秒。如果在这个时间到期了还没有新的 LLDPDU 被收到,则该 TLV 所属的那个 LLDPDU 携带的信息会被从 MIB 中删除。如果收到了新的 LLDPDU,则
- 如果 TTL 不为 0,则会用新收到的 LLDPDU 的信息替换 MIB 库中的相应的信息(即与该 LLDPDU 的发送者相关的 MIB 信息,LLDP 使用
Chassis ID+Port ID 来判断是否来自于同一个源,这也是要求这两者保持不变的原因)。 - 如果 TTL 为 0,则删除相应的 MIB 库中的信息(即与该 LLDPDU 的发送者相关的 MIB 信息)。因此 TTL 为 0 的 LLDPDU 又被称为SHUTDOWN LLDPDU。
每一个 LLDPDU 必须包含且只能包含一个该类型的 TLV。
工作机制
LLDP 是一个用于信息通告和获取的协议,但是需要注意的一点是,LLDP 发送的信息通告不需要确认,不能发送一个请求来请求获取某些信息,也就是说 LLDP 是一个单向的协议,只有主动通告一种工作方式,无需确认,不能查询、请求(比如像 ARP 协议那样请求某个 IP 的 MAC 地址)。
LLDP 主要完成如下工作:
- 初始化并维护本地 MIB 库中的信息。
从本地 MIB 库中提取信息,并将信息封装到 LLDP 帧中。LLDP 帧的发送有两种触发方式,一是定时器到期触发,一是设备状态发生了变化触发。
识别并处理接收到的 LLDPDU 帧。
维护远端设备 LLDP MIB 信息库。
当本地或远端设备 MIB 信息库中有信息发生变化时,发出通告事件。
LLDPDU 发送
发送机制
LLDPDU 的发送可以被如下事件触发:
- 与本地 MIB 信息库相关联的定时器 txTTR 到期时,这将确保远端接收系统中的相关信息不会因为 TTL 到期而过期。
- 本地 MIB 信息库中的信息发生了改变时,会立即发送 LLDPDU,这将保证改变能及时被更新。
- 如果一个“新邻居”被识别,将会启用快速发送机制,在很短的时间内连续发送指定数量(txFastInit,默认值为 4)的 LLDPDU,以确保“新邻居”能被快速更新。如果远端系统 MIB 信息库因为过载(tooManyNeighbors)而不能容纳新的邻居信息,则会为了避免过多的LLDPDU 传输而抑制快速发送行为。
LLDP 的常规发送时间是建立在系统的 Tick 之上的,间隔为 1 秒一个,为了防止在共享介质的 LAN(shared media LAN)中同时出现大量的 LLDPDU(因为接入同一个LAN的多个系统的时间是同步的,因而多个系统上的基于 Tick 的1秒定时器可能同时到期),发送定时器引入了一个随机的抖动,这就使得常规的 LLDP 帧的发送间隔时间的平均值仍是 1 秒,但是具体到某一次到期时间可能并不是准确的 1 秒。
同时为了防止在有多个端口需要发送 LLDPDU 的系统中,所有的端口的定时器都在同一时间到期,因而标准建议将采用某种机制将多个发送实例的定时器到期时间给错开,以避免一个系统在同一时刻发送大量的 LLDPDU。
发送状态机
LLDPDU 的发送状态机如图所示
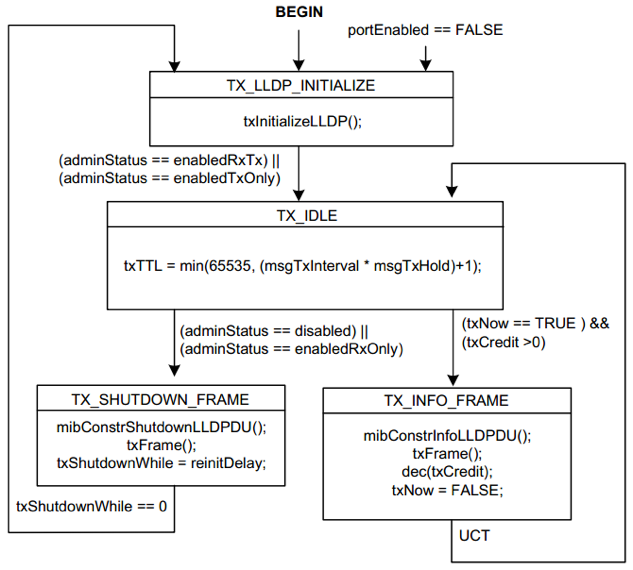
对于该状态机:
- 为了防止过于频繁的重新初始化发送状态机,在 LLDP 的发送状态机中引入了一个延时,该延时限制了在关闭发送状态机后,必须至少等待多长时间才能重新初始化发送状态机。
- 是否发送 SHUTDOWN LLDPDU 由本地的 LLDP 工作状态决定。
- 是否发送正常的 LLDPDU 由 txNow 和 txCredit 决定。这两个变量都由发送定时器状态机更新。txNow 决定是否发送,而 txCredit 则是一个信用量,决定了可以发送的量,如果是 0 则不允许发送,只有大于 0 的值才允许发送,每发送一个该值就减 1。更重要的是在本地信息快速改变时,txCredit 既允许连续发送多个 LLDPDU,但是又对可以连续发送的 LLDPDU 帧数做了限制,这使得本地状态的快速改变可以及时被通告出去,但是又不能无限发送导致网络出现大量 LLDPDU 帧。
发送定时器状态机
LLDP 发送定时器状态机如图所示
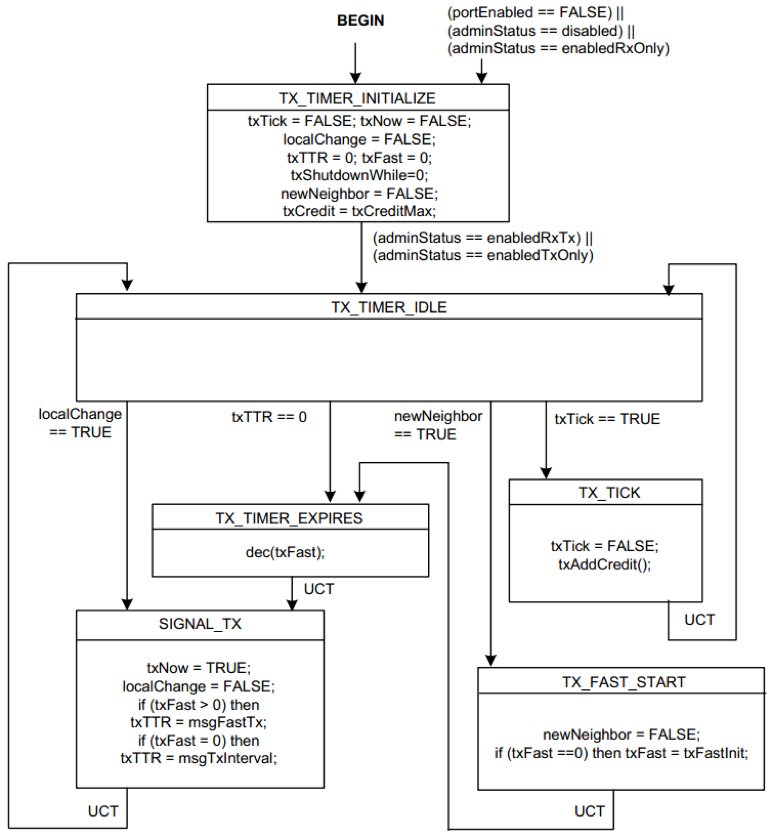
localChange 表示本地信息是否发生改变;txTTR 表示下一次定时器到期的时间;newNeighbor 表示是否发现了新的邻居,并由接收状态设置,由该状态机清除;txTick 表示基于系统时间的1秒定时器是否到期。
对于该状态机:
- SIGNAL_TX 用于触发发送,它会将 txNow 设置为允许发送,并设置本地信息发生改变为 FALSE,如果当前不是在快速发送状态(txFast = 0)就设置发送定时器下次到期时间为 msgTxInterval(msgTxInterval默认为30秒,取值范围1-3600秒),否则设置发送定时器下次到期时间为 msgFastTx(msgFastTx默认值为1秒,取值范围1-3600秒)。
- 如果本地信息发生了改变,就立即进入 SIGNAL_TX。
- 如果定时器到期,则如果 txFast 大于 0,则将其减 1 并进入 SIGNAL_TX,否则直接进入 SIGNAL_TX。
- 如果发现了新邻居,则首先将发现新邻居的标识更新为没有发现新邻居,然后如果当前已经处于快速发送状态就直接进入发送定时器到期状态(以触发一次立即发送),否则设置 txFast 的值为 txFastInit 的值(txFastInit 默认值为 4,取值范围 1-8)。
- 如果基于系统时间的 1 秒定时器到期,则给 txCredit 增加信用量,其最大值为 txCreditMax,txCreditMax 是一个取值在 1 到 10 之间的值,默认值为 5。
这里有取值范围的几个变量都是可配置的变量。
从上述两个状态机的工作状态可以看出,发送定时器状态机用于维护信用量以及是否允许发送 LLDPDU 帧,而发送状态机根据这两个信息来决定是否发送。另外需要注意的是 LLDP 所使用的所有定时器操作都是“基于系统时间的 1 秒定时器的”,每当这个定时器到期时它除了会将 txTick 设置为 TRUE 外,还会处理其它的定时功能。
LLDPDU 接收
接收机制
LLDP 帧的接收由 3 个阶段组成:帧的识别、帧的校验、LLDP 远端 MIB 信息库更新。
帧的识别
由在 LLDP/LSAP(链路服务访问点)进行,检查的内容是帧的目的地是否是 LLDP 的组播 MAC 地址,帧的类型是否是 LLDP。
帧的验证
该过程会首先根据 TLV 的格式定义依次校验 Chassis ID TLV,Port ID TLV, Time To Live TLV,如果这三个 TLV 都存在且有效,才会进一步的解码可选的 TLV 直到遇到 End Of LLDPDU TLV,然后根据获得的信息更新远端 MIB 信息库。
远端 MIB 信息库更新
在前两步都通过之后,LLDPDU 的接收者就需要根据解析出来的信息更新远端 MIB 信息库。在 MIB 信息库中,LLDP 使用 Chassis ID+Port ID 来标识、存储来自不同源的信息。
- 如果远端MIB库中已经有对应于该
Chassis ID+Port ID 的信息,则使用收到的帧中的新的 TTL 来更新 TTL。并用对于收到的新的 LLDPPDU 中的每一种 type,如果有变化就进行更新,如果某种 type 原来不存在,则需要将其添加到 MIB 库中。 - 如果实现不支持某种类型的 type,则
- 如果 type 不是 127,则按照基本 TLV 的格式将其存储到远端 MIB 库,存储格式为 type,length,value。
- 如果 type 是 127,则按照组织定义 TLV 的格式将其存储到远端 MIB 库,存储格式为 type,length,value,OUI,组织自定义子类型,以及信息域。
更新时,如果需要添加新的 Chassis ID+Port ID 的表项,或者为某个 Chassis ID+Port ID 添加新的 TLV,则可能遇到没有内存的问题,标准没有规定必须如何处理,只是给出了一些建议:
- 忽略新的 LLDPDU 的信息
- 删除最旧的信息以释放空间给新的信息
- 随机删除一些旧的信息以释放空间给新的信息
LLDPDU 携带的 TTL(Time To Live)值会影响接收端的处理方式,如果它不为 0,则更新相应信息的老化时间,如果接收到的 LLDPDU 中的 TTL 等于 0,则将立刻老化掉相应的信息(即与该 LLDPDU 的发送者相关的MIB信息)。
如果一个 Chassis ID+Port ID 标识的信息的 TTL 超时,则相应的 MIB 信息会被删除。
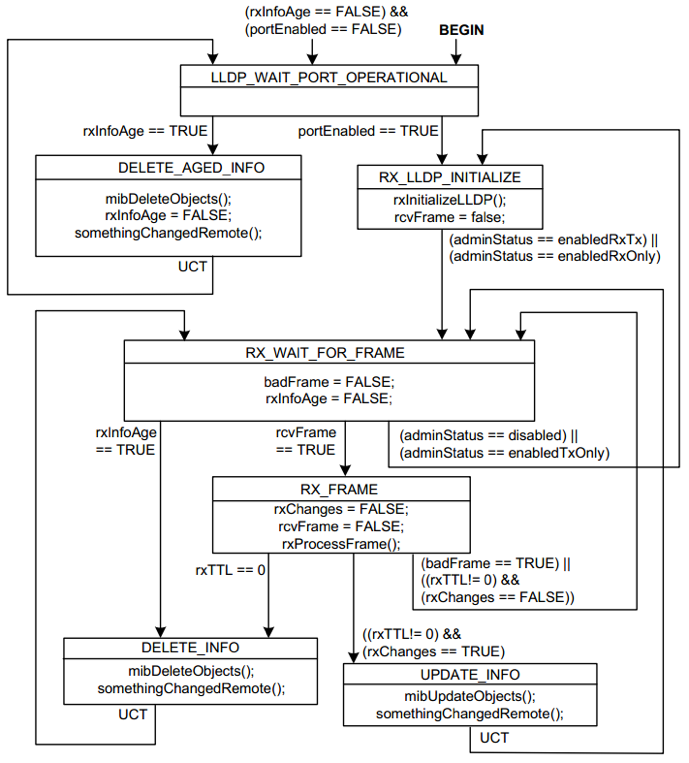
接收状态机
LLDPDU 的接收状态机如图所示
LLDP 工作模式
LLDP 可以工作在多种模式下:
- TxRx:既发送也接收 LLDP 帧。
- Tx:只发送不接收 LLDP 帧。
- Rx:只接收不发送 LLDP 帧。
- Disable:既不发送也不接收 LLDP 帧(准确的说,这并不是一个 LLDP 的状态,这可能是 LLDP 功能被关闭了,也可能是设备就不支持)。
由于 LLDP 可以单独工作在发送或接收模式下,因此 LLDP 协议的实现需要支持单独初始化发送或者接收功能。当工作模式发生变化时,需要根据老的/新的工作模式来关闭/打开发送或者接收的功能。
至此,LLDP 相关知识点已经介绍完,希望对大家有所帮助。
]]>